
Pré-traitement des vidéos de tests utilisateurs – uniformisation de la qualité audio – Partie 2/2
Pré-traitement des vidéos de tests utilisateurs – uniformisation de la qualité audio – Partie 2/2
Dans la première partie de l'article, nous avons vu comment standardiser le format d’encodage audio/vidéo et normaliser le volume d'écoute. Dans ce chapitre, nous expliquerons comment détecter et atténuer les pics de volume parasites.
Détection et atténuation des pics de volume parasites
Pour remédier au problème de normalisation nous avons développé un algorithme qui permet de détecter puis d’atténuer automatiquement les pics parasites dans les formes d’onde. La procédure retenue est la suivante :
1. Estimer automatiquement un seuil d’amplitude limite
Tout ce qui dépasse ce seuil est considéré comme un pic parasite. Le calcul de ce seuil est effectué par un algorithme développé en interne et basé sur des méthodes statistiques appliquées aux données de la forme d’onde.
2. Ramener tous les pics parasites à ce seuil en appliquant un limiteur
Un limiteur est un algorithme couramment employé dans le monde de l’ingénierie audio pour “limiter” le volume du son lorsqu'il dépasse un seuil donné.
Les limiteurs peuvent être “soft” c’est-à-dire appliquer une atténuation des pics douce et progressive en fonction de leur amplitude, ou “hard” c’est-à-dire ramener tous les pics qui dépassent le seuil à la valeur exacte du seuil.
C’est donc un “hard limiter” qui nous intéresse ici. Le limiteur intégré au programme open-source FFmpeg fait très bien l’affaire (moyennant quelques réglages pour éviter que le son ne “sature”)
3. Normaliser la forme d’onde
Nous normalisons le volume à -3 décibels (voir paragraphe précédent)
Appliqué à notre exemple précédent, cela donne :
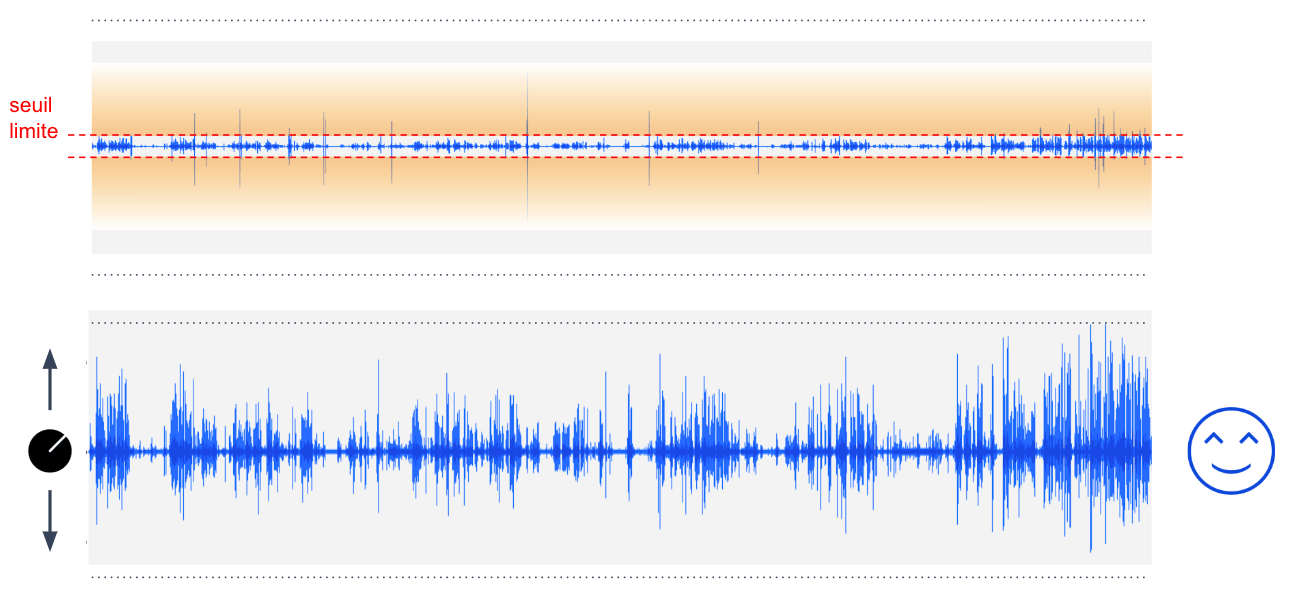
Grâce à ces optimisations, plus besoin d’ajuster constamment le volume d’écoute pendant le visionnage, et bye bye les problèmes d’encodage! Nos clients et nos expert UX peuvent pleinement se concentrer sur leur travail d’analyse :)
Pour aller plus loin
Beaucoup d’autres leviers d’optimisation de la qualité audio existent pour améliorer le confort de visionnage de nos vidéos de test, à commencer par l’atténuation des divers bruits de fond ambiants ou électroniques et l’ajustement fréquentiel (égaliseur) bien que ce dernier soit particulièrement compliqué à automatiser. Ce sont deux pistes de recherche que nous allons considérer dans le futur.
D’autre part, nous travaillons en parallèle sur de nouvelles thématiques liées à l’intelligence artificielle, ce qui nous a amené à revoir notre pipeline de pré-traitement de l’audio avec d’un côté un fichier audio/vidéo normalisé destiné au visionnage “humain” par les clients et experts UX, et d’autre part un fichier audio brut à destination de nos algorithmes d’intelligence artificielle, avec comme première application la transcription automatique de l’audio en texte (speech-to-text) qui vous sera présentée dans un prochaine news.
Merci d’avoir lu cet article et à bientôt pour un prochain point d’actualité au cœur de notre département R&D !
 Published by :
Published by :