
Enrichissement des vidéos de tests utilisateurs avec du speech-to-text
Enrichissement des vidéos de tests utilisateurs avec du speech-to-text
Depuis quelques années, le mot “intelligence artificielle” ne fait plus figure de concept obscur au sein des entreprises; autrefois perçus comme une technologie de pointe réservée à certains cracks de l’informatique ou élites de la Silicon Valley, les algorithmes “intelligents” et “auto-apprenants” se sont démocratisés à vitesse grand V depuis que les performances matérielles de nos machines permettent la collecte et le traitement de très grandes quantités de données dans des temps respectables pour un humain.
Les algorithmes de machine learning et de deep learning, dont les premiers travaux remontent aux années 50, ont connu un essor considérable cette dernière décennie et sont désormais rendus accessibles aux développeurs via des bibliothèques logicielles assez simples à utiliser.
Pour pouvoir tirer tout le potentiel de ces technologies et faire croître leur activité, les entreprises font aujourd’hui appel à des data scientists pour comprendre et déployer ces algorithmes au sein de leur structure.
Transcription des fichiers audio
Parmi eux, les algorithmes de transcription audio → texte (speech-to-text en anglais) sont utilisés pour gérer ses objets connectés par commande vocale, pour communiquer avec des chatbots ou pour générer automatiquement des sous-titres dans des vidéos. Le principe est simple ; on envoie un fichier ou un stream audio à un algorithme et on récupère en sortie le texte correspondant.
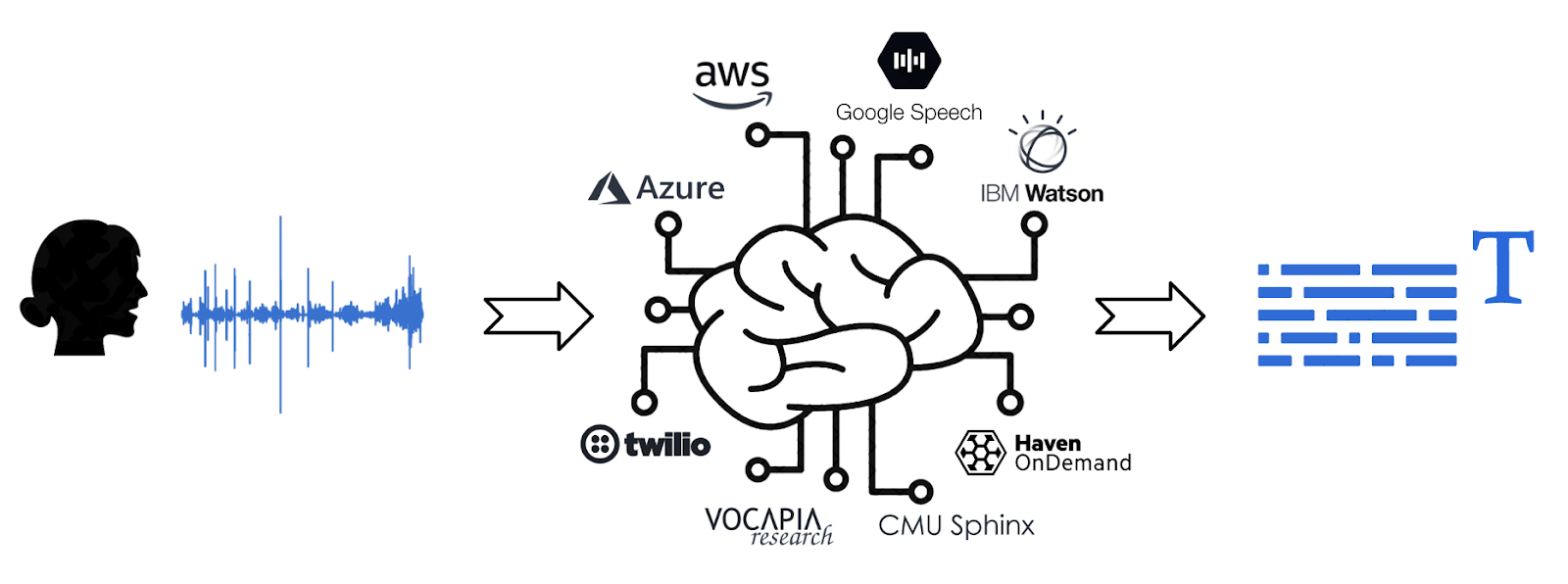
Cependant, développer un algorithme de speech-to-text performant est une tâche très complexe car nécessitant d’une part de solides connaissances techniques (mathématiques, statistiques, programmation, deep learning) et d’autre part beaucoup de données audio et textuelles pour entraîner l’algorithme, ce qui rend la tâche abordable par seulement quelques grandes entreprises du numérique et startups spécialisées en intelligence artificielle.
Heureusement certaines de ces entreprises spécialisées (et les géants du web en particulier) vendent leurs services en fournissant un accès direct à leurs algorithmes de speech-to-text via une API (Application Programming Interface). Il suffit d’envoyer un fichier audio à l’API et on récupère directement en sortie un fichier avec le texte et des informations enrichies (timestamp et degré de confiance associé à chaque mot...), et tout ceci en s’affranchissant des concepts techniques et algorithmiques sous-jacents !
Du point de vue d’une entreprise dont le cœur du métier n’est pas intrinsèquement lié au domaine de l’intelligence artificielle, il est souvent bien plus pratique et rentable de faire appel à un service externe que d’embaucher une équipe de data scientists pour développer l’algorithme en interne, qui au final sera probablement moins performant que ceux proposés par les sociétés tierces qui travaillent d’arrache pied pour optimiser et mettre continuellement à jour leur technologie de transcription.
Et chez Testapic?
Chez Testapic, nous utilisons actuellement le service proposé par Google “Google Cloud Speech” pour retranscrire les enregistrements audio issus de nos tests utilisateurs vidéos. Le service gère plusieurs langues (dont le français) et propose des options de customisation intéressantes comme la reconnaissance de mots de vocabulaire ou phrases clés spécifiques à notre domaine d’activité, ou de spécifier le type de source audio (PC, smartphone ...) et la distance moyenne entre l’utilisateur et le micro pour profiter de performances accrues de l’algorithme.
Notre équipe data / R&D travaille actuellement sans relâche pour proposer une expérience des tests utilisateurs à distance enrichie des dernières innovations en matière d’intelligence artificielle.
Dans un futur proche, nos clients et experts UX pourront ainsi bénéficier d’un système de sous-titrage automatique des vidéos de tests avec navigation synchronisée entre la vidéo et le texte. D’autre part les transcriptions serviront de base pour alimenter des algorithmes de traitement du langage (NLP) développés en interne par nos data scientists, toujours dans une logique d’enrichissement automatique des données de tests.
Il sera par exemple possible de repérer les principaux points bloquants dans les interfaces et applications de nos clients en amont de la phase d’analyse “humaine”, de filtrer les contenus non pertinents et, à terme, d’automatiser certains jalons de la phase d’analyse des résultats.
D’ici-là je vous dis à bientôt pour un prochain point d’actualité côté R&D !
 Published by :
Published by :