
Atomic research : Définition et utilisation
Atomic research : Définition et utilisation
Vous en avez sûrement entendu parler. L'Atomic research est la nouvelle méthode censée révolutionner le monde de l'UX Research. Développée par Daniel Pidcock, cette méthodologie permet de repousser les limites du stockage de données en proposant une nouvelle méthode d'archivage.
Table of Contents
Qu'est-ce que l'Atomic Research ?
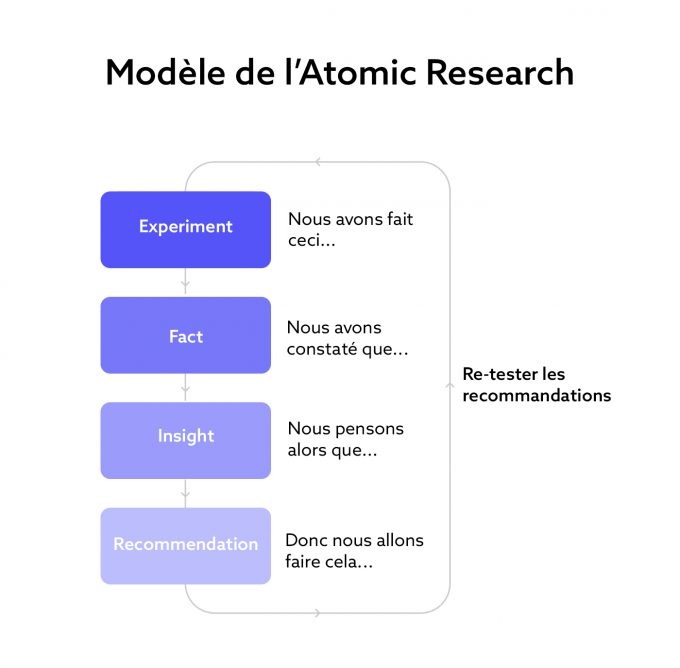
L'atomic research est un nouveau concept permettant de "ranger" les connaissances UX à l'aide de 4 éléments distinctifs : Experiments, Facts, Insights et Recommendations. Le but de cette méthodologie est de faciliter le stockage des données en les organisant de manière rigoureuse pour plus facilement les retrouver.
- Experiments : Correspond à la source de l'information, dans quel cadre avons-nous collecté cette information. "Nous avons fait ceci..."
- Facts : L'observation, le verbatim ou bien la statistique que nous avons relevé. C'est le fait que nous avons collecté. "Nous avons constaté que..."
- Insights : C'est l'analyse du fact précédemment défini. L'insight a pour but d'expliquer le fait, d'en trouver la source. "Nous pensons alors que..."
- Recommendations : La ou les actions à mettre en place pour régler l'irritant décelé. "Donc nous allons faire cela..."
Ainsi, au moment d'archiver chaque nouvelle connaissance UX, il vous faudra les fractionner en 4 éléments. Ceci vous permettra alors de garder le contexte dans lequel l'information a été collectée, et de plus facilement la réutiliser dans le futur.
Cas pratique
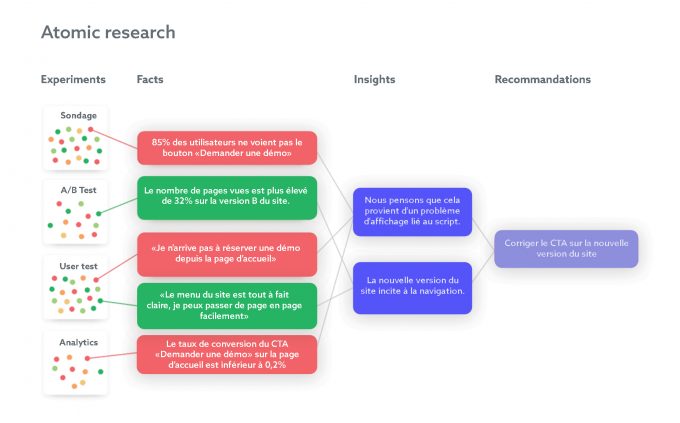
Afin d'imager les explications précédemment énoncées, voici un exemple : Lors d'un test utilisateurs, vous constatez que 85% des internautes ne voient pas votre bouton "Demander une démo" sur votre page d'accueil.
En suivant la méthodologie de l'Atomic Research vous allez alors archiver l'information de cette manière :
- Experiments : Test utilisateurs réalisé sur notre page d'accueil dans le cadre d'un audit réalisé en 2022
- Facts : 85% Des internautes ne voient pas le CTA "Demander une démo" sur la page d'accueil du site.
- Insights : Nous pensons que cela provient d'un problème de saillance du bouton qui ne respecte pas les normes de contraste du W3c.
- Recommendations : Il conviendrait donc d'augmenter le niveau de contraste du CTA et de mettre un fond de couleur plus foncé.
Modèle de l'Atomic research
Les tags en Atomic Research
Afin de bien vous y retrouver dans vos connaissances UX, il reste primordial de bien les répertorier en amont. Pour cela, il est conseillé de définir un modèle de nomenclature pour tagger vos connaissances, et de le respecter rigoureusement.
Par exemple, pour tous les sujets touchant aux formulaires. Choisissez une nomenclature qui les distinguera facilement des sujets liés à la page d'accueil ou à votre arborescence.
De plus, il est recommandé de créer une cinquantaine de tags maximum. Le but ici est d'éviter qu'ils ne soient trop nombreux, au risque de vous y perdre, ni trop peu afin de bien définir le type de donnée collectée.
Avec un plan de taggage pertinent et défini en amont, il vous sera très facile de retrouver vos données dans un Airtable, Coda ou encore dans un document Gleanly.
Atomic Research, quel intérêt pour la recherche utilisateur ?
Pour la recherche utilisateur, cette nouvelle approche offre de nouvelles possibilités. Mais surtout, cette nouvelle méthode résout de nombreux problèmes. Le stockage des données, le partage de l'information ou encore la prise de décision sont 3 aspects de la recherche utilisateur que l'Atomic Research peut grandement améliorer.
Stockage des données
En proposant l'Atomic Research, Daniel Pidcock, permet en premier lieu de pouvoir facilement retrouver les données collectées.
En effet, il arrive très régulièrement que des informations que vous cherchiez soient déjà à votre disposition, cachées au fond d'un dossier. Seulement par manque de méthode au moment de l'archiver, il est impossible de les retrouver. Bien souvent la conséquence est qu'une nouvelle recherche utilisateur est réalisée.
Contrairement à un Google Drive, où les documents finissent par se perdre dans les méandres des serveurs, l'Atomic Research et son système de taggage permettent en théorie de stocker une infinité d'informations sans que celles-ci ne soient perdues.
En proposant un archivage de l'information très visuelle, la méthode proposée par Daniel Pidcock permet de visualiser en un clin d'œil l'ensemble des retours liés à un tag.
Organisation visuelle de l'Atomic research
Partage des informations
Décider de mettre en place une méthodologie d'Atomic Research, c'est faire le choix de rendre vos données issues de la recherche utilisateur accessibles à toute votre entreprise. Cela permet le décloisonnement des équipes, mais surtout cela rend possible l'enrichissement des données.
En effet, en partageant les données collectées à l'ensemble de vos équipes, ces dernières vont venir compléter et étoffer vos connaissances UX en apportant leurs propres constats.
Reprenons notre exemple précédent sur le cas du bouton "Demander une démo": Si par exemple, vos développeurs remarquent que le script censé afficher votre CTA bug au moment d'afficher le fond de couleur de votre CTA, ces derniers seront en mesure d'enrichir votre connaissance UX en complétant vos précédentes observations. Leur constat complétera alors ce que vous aviez décelé et permettra de régler le problème rapidement.
En partageant l'ensemble de vos connaissances UX à toutes vos équipes, vous vous prémunissez de potentielles dépendances à des collaborateurs spécialistes d'un sujet. L'information n'est alors plus conservée par une personne, mais par tout le monde.
Faciliter la prise de décision
L'Atomic Research possède aussi l'avantage de permettre de quantifier le nombre de fois qu'un irritant est décelé. En effet, étant lié à des tags, et étant structuré de manière organisée, il est très simple de vérifier si un irritant utilisateur apparait plusieurs fois. L'ajout d'un système de scoring, comme ce qu'a pu faire France Info, peut même aider à quantifier ces constats, et à prendre des décisions.
Si par exemple vous constatez qu'un même irritant non bloquant revient régulièrement, il peut être tout de même pertinent de le prioriser par rapport à des soucis plus gênants mais moins récurrents.
Un gestionnaire de la connaissance UX peut aussi servir à justifier des actions ou choix mis en place. En archivant l'ensemble des connaissances UX, il est alors possible de retracer le chemin qui vous a guidé à prendre une telle décision. "Nous avons mis en place cette action suite l'ensemble de ces constats".
Quel outil utiliser pour faire de l'Atomic Research ?
Il existe une multitude d'outils permettant de mettre en place l'Atomic Research. Cela commence du simple post-it, en passant par un fichier Excel, jusqu'à un outil totalement dédié. Par exemple, si vous n'avez pas de budget, peu de collaborateurs et que vous travaillez en physique. Il est possible à partir d'un tableau blanc et de quelques post-it de mettre en place une telle méthodologie.
Bien évidemment, cette approche sera vite dépassée dès le moment où la quantité de données augmentera. Cependant des solutions plus puissantes comme Airtable, Coda, voire Notion existent pour des plus grosses équipes.
Hormis, Gleanly, aucun outil n'est spécialement dédié à l'Atomic research, mais certains peuvent tout à fait faire l'affaire. Plusieurs grands groupes passent par exemple par Airtable, France Info de son côté a choisi Coda.
Les options sont donc multiples. Cependant nous pourrions tout de même vous conseiller de passer par les 3 solutions les plus répandues (Gleanly, Airtable et Coda). Notion, par exemple est plus compliquée à paramétrer pour le taggage, et Excel peut rapidement devenir complexe.
Enfin petite anecdote, nous avons déjà vu certaines équipes utiliser Figma en détournant son utilisation et en ajoutant des extensions. Le plus important reste ainsi de choisir l'outil qui répond le mieux à vos besoins.
Nos bonnes pratiques
Maintenant que vous savez ce qu'est l'Atomic Research il est temps pour nous de vous donner nos conseils pour réussir sa mise en place.
Archivage de la connaissance UX
Tout d'abord au moment de mettre par écrit vos nouvelles connaissances UX, nous ne pouvons que vous conseiller de mettre du contexte. Il ne s'agit pas d'écrire une page par élément bien sûr. Mais, il sera toujours plus facile pour vous après d'avoir "Test utilisateurs réalisé sur notre page d'accueil dans le cadre d'un audit réalisé en 2022" plutôt que "Test utilisateurs".
Cela vous permettra notamment de faciliter la compréhension des facts et insights associés à chaque experiment.
Au moment de rédiger les insights, il existe une erreur assez répandue qui est de rester trop factuel. Malheureusement, encore beaucoup d'UX ne réalisent pas de réelle analyse à cette étape, ils restent sur des faits.
Pour rappel la partie Insight représente votre analyse, ceci se rapproche d'une opinion. Dans votre tête votre phrase doit commencer par "Nous pensons que..."
Tags et nomenclature
Pour ce qui est des tags nous insisterons sur la rigueur. Comprenez bien ici qu'il sera toujours plus simple, pour vous, de retrouver et d'organiser vos données, si vous respectez votre nomenclature et que votre plan de taggage est bien ficelé.
Nous le répétons, mais créer plus de 50 tags vous fait prendre le risque de ne plus vous y retrouver. Gardez un plan de taggage cohérent et compréhensible par tout le monde est un prérequis pour mettre en place une méthodologie d'Atomic research.
 Published by : Julien Hennig - Classés dans : UI / UX (Design & Conception)UI / UX (Design & Conception)
Published by : Julien Hennig - Classés dans : UI / UX (Design & Conception)UI / UX (Design & Conception)